안녕하세요! 조엘입니다!
오늘은 HashMap과 HashSet이 어떻게 데이터를 저장하는지에 대해 한번 알아보아요! 💪
피드백 환영입니다! 댓글 달아주세요 :)
*** HashMap ***
HashMap은 Map 인터페이스를 구현한 컬렉션이에요.
Map 인터페이스는 Key Object와 Value Object를 같이 저장하는 데이터 구조예요.
Key Object를 기반으로 데이터를 저장하고, 접근하기 때문에 Key Object는 고유해야 해요.
따라서 Key Object는 중복해서 저장할 수 없어요.
또한 저장 순서와 출력 순서를 보장하지 않는 데이터 구조라고 알려져 있어요.
*** HashSet ***
HashSet은 Set 인터페이스를 구현한 컬렉션이에요.
HashSet은 내부적으로 HashMap으로 구현되어 있어요.
Key Object에 저장하고 싶은 객체를 저장하고, Value Object에는 dummy data를 넣어 두어요.
위에서 살펴본 바와 같이 Key Object는 고유해야 하기에, 중복으로 저장되는 일은 없어요.
또한 HashMap과 같이, 저장 순서와 출력 순서를 보장하지 않는 데이터 구조예요.
*** HashMap/HashSet은 순서를 보장하여 출력한다? ***
위와 같이 HashMap/HashSet에 대해 알고 있었는데, 하나 흥미로운 사실을 발견했어요.

HashSet 같은 경우, 데이터의 저장 순서와 출력 순서가 무작위로 알고 있었는데 웬걸?
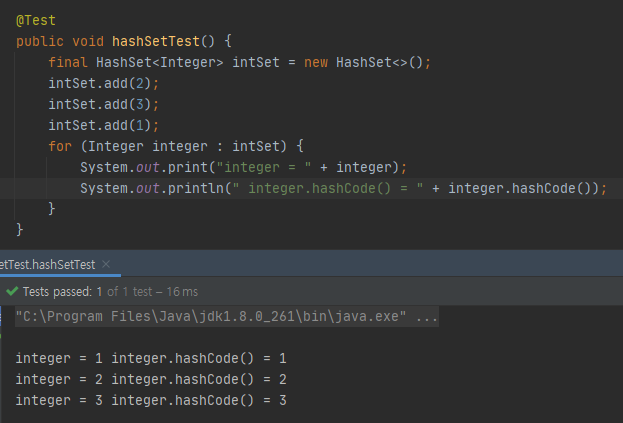
intSet을 출력해보면 매번 [1, 2, 3] 이 나오는 것을 알 수 있었어요.
갑자기 조금 쎄 하더라고요? 분명히 HashSet은 무작위로 저장되어 순서가 보장이 안될 텐데?
그리고 왜 [2, 3, 1], [2, 1, 3] 도 아니고, 하필 순서가 아주 이쁜 [1, 2, 3] 일까?
완전 정렬된 느낌이 들게 말이야! 🙄
그래서 HashMap/HashSet의 원리를 찾아보게 되었어요.
위에서 HashMap을 소개하며 언급한 멘트를 다시 가져올게요.
Key Object를 기반으로 데이터를 저장하고, 접근하기 때문에 Key Object는 고유해야 해요.
이번 포스팅에서 "Key Object를 기반으로"에 녹아있는 속 뜻을 함께 알아봅시다.
*** hashCode ***
자바에는 객체를 식별할 수 있는 hashCode라는 것이 있어요.
Object 클래스에 정의되어 있는 hashCode 메서드는 기본적으로 객체의 메모리 번지를 이용해서, 객체의 고유한 값을 정수로 만들어 반환해주게 되어요. 물론 hashCode 메서드는 Object에 정의되어 있는 메서드이기 때문에 다른 클래스에서 필요에 따라 오버라이딩을 해줄 수 있어요.
hashCode는 객체 별로 구분할 수 있는 고유한 값을 만들어 주기 때문에, 객체의 정체를 알아내고 접근하는데 유용하게 쓰여요. 따라서 HashMap/HashSet에서도 hashCode를 사용해요.
그렇다면 HashMap/HashSet은 객체의 hashCode가 작은 순서대로 차곡차곡 저장하는 걸까요?
*** 배열로 이루어진 HashMap ***

해당 예시에서는 가장 hashCode가 큰 "11"이 가장 먼저 출력되는 것을 볼 수 있었어요.
어라..? 제 유추가 틀렸군요! 어디가 문제였을까요?
HashMap/HashSet은 데이터 접근에 O(1)을 보장하는 자료구조라고 들어보셨을 거예요.
어떻게 O(1)을 보장할 수 있었을까요?
O(1)으로 데이터를 접근하는 또 다른 방식으로 어떤 자료구조가 있을까요?
바로 index를 확실히 알고 있는 배열에 접근할 때입니다.
HashMap/HashSet 역시 O(1)을 보장하기 위해 배열을 사용해요.
오! 그러면 hashCode가 정수로 반환된다고 했으니, 정수가 표현하는 2^32 사이즈의 배열을 만들어 놓고,
Key Object의 hashCode로 배열의 index를 구해 삽입하고, 조회하는 걸까요?
*** 버킷 수 ***
아니요! 너무 비효율 적이잖아요!
아까 예시에서 객체 3~4개를 저장했는데, 이를 위해 2^32개의 배열을 선언하면 메모리 손해가 엄청나겠죠?
여기서 우리가 포커스를 맞춰야 할 부분은 바로 버킷 수예요.
여기서 버킷 수는 배열의 크기라고 생각하시면 돼요.
HashMap을 기본적으로 선언하게 되면, 디폴트 버킷 사이즈가 16으로 지정이 되어요.
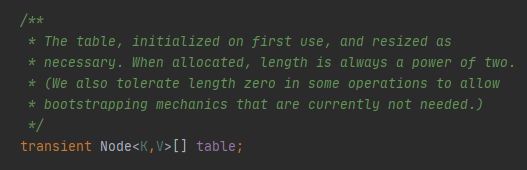
즉 16개의 Node<K, V>가 들어갈 수 있는 배열이 선언이 된 것이죠.
자, 이제 우리의 목표, "Key Object를 기반으로"의 속뜻을 풀이합니다.
우리는 Key Object를 알맞은 버킷에 저장하기 위해 hashCode를 사용한다고 언급했어요.
여기에 한 차례 가공이 더 필요해요.
바로 hashCode를 버킷 수로 나눈 나머지를 배열의 index로 사용하는 것이죠!
HashMap을 기본적으로 생성하게 되면, 디폴트 버킷 사이즈가 16이에요.
Key Object의 hashCode를 16으로 나눈 나머지는 0~15 중 하나가 될 것이고,
해당 index에 우리의 Key Object - Value Object를 저장해 둘 수 있겠네요!
(해시 충돌 등을 어떻게 처리하는지는 아래 네이버 포스팅을 참고하세요!)

아하! 이제 해당 코드의 동작이 이해가 되는군요.
"11"의 해시 코드는 1568인데, 이를 버킷수 16으로 나누면 0이라서 배열에 가장 앞에 저장했던 거군요!
*** 로드 팩터 ***
그렇다면, 또한 HashMap이 저장 순서와 출력 순서를 보장하지 않는다는 것은 거짓말일까요?
아니요! 사실 저장 순서/출력 순서가 보장되지 않는다는 말은 맞는 말이에요.
이는 HashMap의 또 하나의 중요한 요소 로드 팩터라는 친구 때문에 그래요.
HashMap을 기본적으로 선언했을 시, 갖게 되는 버킷 수는 16개라고 얘기했어요.
하지만 16개 보다 더 많은 데이터가 들어오면 어떻게 할까요?
당연히 버킷 수를 늘려, 더 많은 데이터를 받아들이도록 해야겠죠?
그렇다면, HashMap이 가지고 있는 버킷 중에 얼마나 차야 추가적으로 데이터를 저장할 공간을 확보해 놓을까요?
70 프로? 80 프로? 90 프로?
여기서 "얼마만큼 차야"가 로드 팩터입니다.
HashMap을 기본적으로 선언하게 되면 갖게 되는 디폴트 로드 팩터는 0.75에요.
즉 75%의 버킷이 차면 추가적으로 데이터를 저장할 공간을 확보하게 되는 것이죠.
로드 팩터를 초과해 데이터가 저장되면, HashMap은 현재 버킷 개수의 2배만큼 용량을 늘려요.
여기서 바로 순서가 보장이 안된다는 것이에요.
아까까지만 해도 Key Object의 hashCode 값에 16으로 나눈 나머지로 인덱스를 구해서 배열에 저장했었는데,
어느덧 버킷의 75%가 차 버려서 용량이 2배로 늘어 32개의 버킷이 생긴다면,
Key Object의 hashCode 값에 32로 나눈 나머지로 인덱스를 구해 배열에 저장해야 할 것이에요.
이 과정에서 분명히 위치가 바뀌는 Object도 생길 것이고, 그 결과 순서가 보장이 안 되는 것이죠.
다음과 같은 예시가 그래요.
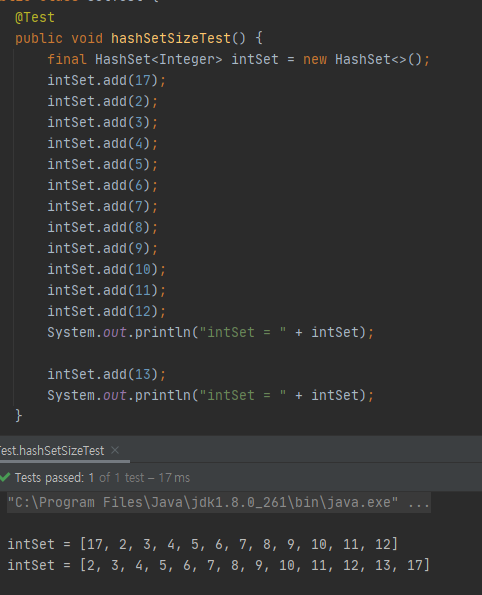
intSet을 처음 출력할 때에는 분명히 처음에 있던 17이, set에 데이터가 하나 추가되면서 맨 뒤로 간 것을 볼 수 있어요.
17의 경우 hashCode가 17인데,
HashSet의 버킷 개수가 16이었던 시점에는 17 % 16 = 1 이여서 가장 먼저 출력이 되었던 반면,
HashSet의 버킷 개수가 32이었던 시점에는 17 % 32 = 17 이여서 맨 뒤에 출력이 된 것을 알 수 있어요.
따라서, 순서가 보장이 안 된다는 말이 아주 맞는 말이었다는 것이죠!
*** 결론 ***
이제 결론입니다.
HashMap/HashSet의 원리에 대해 알아보았는데, 그럼 이를 어떻게 써야 할까요?
HashMap/HashSet이 데이터의 순서를 보장하지 않는다는 것은 맞는 말이에요.
따라서 데이터의 저장 순서를 기억해야 하는 경우, LinkedHashMap/LinkedHashSet 을 사용하세요.
HashMap/HashSet과 더불어 Doubly-Linked-List로 데이터 삽입 순서를 기록해 둔다고 하네요.
HashMap/HashSet을 쓰는 경우는, 데이터의 저장 및 출력 순서가 중요하지 않고,
데이터의 존재 유무가 그 자체가 중요한 경우가 될 텐데요.
이 경우 데이터가 어느 정도 저장될지 안다면 HashMap 선언 시 미리 버킷수를 지정해 두는 것이 좋아요.
그냥 아무 생각 없이 HashMap을 선언해서 16개의 버킷을 사용하다가,
데이터가 늘어나면서 로드 팩터를 초과해 버킷 수를 늘려주는 것에는 추가 연산과 오버헤드가 발생하니까요.
참고: d2.naver.com/helloworld/831311
'프로그래밍 언어 > Java' 카테고리의 다른 글
| 저는 GC가 처음이라니까요? (0) | 2021.10.02 |
|---|---|
| 저는 어노테이션이 처음이라니까요? (2) | 2021.06.11 |
| Reflection API (4) | 2021.06.09 |
| 저는 JVM이 처음이라니까요? (6) | 2021.05.28 |
| Java Code Conventions (0) | 2020.11.24 |




댓글