안녕하세요 조엘입니다! 시험 기간이라서 오랜만에 포스팅이네요ㅜㅜ
운영체제 5단원에 대해 공부해 보았습니다. 1부, 2부로 나뉘어져 있습니다!
Abraham Silberschatz의 Operating System Concepts 10th edition과 학부 수업을 듣고 정리한 내용입니다. 오개념이 있다면 알려주세요~~
우선 공부하면서 여러 스케줄링에 대한 용어가 혼동되었다. 유튜브를 찾다보니 정리를 잘해주신 최희준 교수님의 강의를 찾을 수 있었다. 여기서 아주 깔끔하게 정리해주신다.
Job 스케줄링: 디스크에 있는 프로그램이 메모리에 준비상태로 진입하는 것을 조율
CPU 스케줄링: 실행할 프로세스를 어떤 CPU에 할당해 줄 것인가를 조율 (멀티 코어 등에서 필요)
프로세스 스케줄링: 메모리에 준비 상태로 있는 프로세스들 중 디스패처를 통해 CPU에 실행 상태로 할당되는 것을 조율
내가 공부하면서 헷갈린 부분은 CPU 스케줄링과 프로세스 스케줄링이 같은 말처럼 쓰이는 것이었다.
여기 기초 운영체제를 배울 때에는 단일 코어라고 가정하고 적혀있어서 내가 헷갈린거 같다.
여기 포스팅에서도 단일 코어 OS를 주로 다루니, CPU 스케줄링과 프로세스 스케줄링을 비슷한 개념으로 생각하고 우선 읽으셔도 될 것 같다. 이제 5단원을 복습해보자.
<스케줄링?>
다중 프로그래밍을 지원하는 이유가 CPU 이용률을 최대화하기 위함이였음을 기억하자! CPU는 항상 실행중인 프로세스가 있었으면 하는 것 이다. 메모리에 다수의 프로세스를 유지하고 있는데 지금 CPU에서 실행하는 프로세스가 대기해야한다? 그러면 가차없이 다른 프로세스를 실행해야 이득인 것이다.
CPU는 컴퓨터의 자원 중 가장 중요한 자원 중에 하나이기에, CPU 스케줄링은 OS 설계에 핵심이 된다!
<CPU-I/O 버스트 사이클>
프로세스는 일반적으로 CPU 실행, I/O 대기의 사이클로 이루어 진다. 어떤 프로세스는 CPU를 오래도록 써야하는 프로세스일 것이고(CPU 버스트가 긺), 또 다른 프로세스는 I/O 대기 시간이 긴 프로세스(I/O 버스트가 긺)일 수도 있다.
이러한 프로세스의 특성들을 고려하여 CPU 스케줄링 알고리즘을 정해야 한다!
<선점/비선점>
프로세스들을 스케줄링 하는데 크게 2가지 개념이 등장한다.
- 선점형 스케줄링: 현재 프로세스의 종료 유무 상관 없이 새로운 프로세스가 CPU 점유 가능
- 비선점형 스케줄링: 현재 할당된 프로세스가 다 끝나야 다음 프로세스가 CPU 점유 가능
현재 대다수의 운영체제는 선점형 스케줄링을 사용한다. 비선점형 스케줄링 보다 빠른 응답시간을 보장하기 떄문이다. 하지만 선점형 스케줄링은 Race Condition을 유발하게 되는데, 이에 대한 해결은 6단원에서 다루게 된다.
<디스패처>
디스패처는 CPU 코어의 제어를 프로세스 스케줄러가 선택한 프로세스에게 주는 모듈이다. 디스패처가 할 일은,
1. 한 프로세스에서 다른 프로세스로의 Context switch
2. User mode로의 전환
3. 프로세스의 재 시작을 위해 User program의 적당한 위치로 이동 시키기
<스케줄링 기준>
프로세스는 많고, CPU는 적다. 어떤 기준으로 프로세스들을 스케줄해야 좋은 알고리즘이 되는 것일까?
기준은 다음과 같다.
1. CPU utilization - MAX
2. Throughput (완료된 프로세스 갯수/단위 시간) - MAX
3. Turnaround time (프로세스의 제출 시간~완료 시간) - min
4. Waiting time (준비큐에서 대기하며 보낸 시간의 합) - min
5. Response time (프로세스의 제출 시간~응답의 시작 시간) - min
이제 하나씩 스케줄링 기법을 알아보자. 준비 큐에 있는 프로세스 중 어떤 것을 CPU 코어에 할당해 줄까?
<First-Come, First-Served Scheduling>
이 방식은 비선점 방식이다. 먼저 요청이 온 프로세스를 다 처리해주고 그 다음 프로세스한테 넘어가는 방식이다.
장점
우선 직관적이고 쉽다는 점이다.
단점
만약 실행 중인 프로세스가 미친듯이 길면, 뒤의 프로세스들은 다같이 실행이 미뤄진다는 점이다(Convoy effect). 이는 CPU utilization을 떨어뜨리고, 평균 대기시간의 편차를 크게 만든다.
<Shortest-Job-First Scheduling>
이 방식은 선점/비선점 두 가지 방식 모두로 구현 가능하다. 이 스케줄링 방식은 가장 짧은 CPU 버스트를 가진 프로세스를 우선적으로 수행하는 방식이다.
장점
평균 대기시간이 최소로 보장이 된다.
단점
CPU 버스트를 계산하기가 어렵다. 이를 계산하고자 이전 실행 시간(history)와 예상 CPU 버스트(prediction)의 값을 섞어서 계산하는 방식을 책에서 소개해준다.
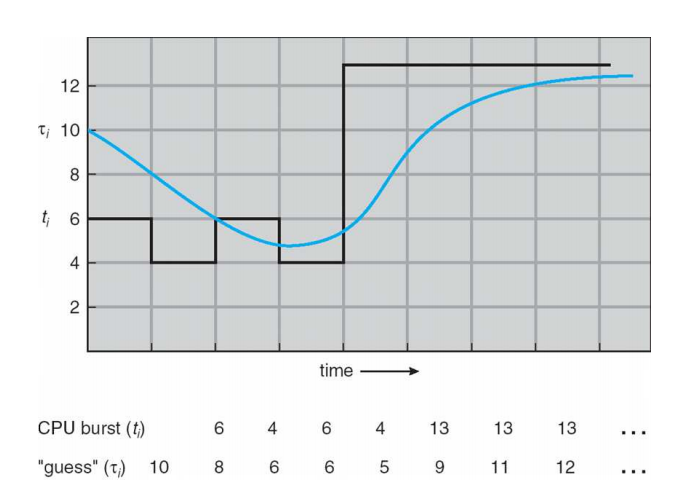
<Round-Robin Scheduling>
이 방식은 선점 방식이다. 선입 선처리 방식에 타임 슬라이스를 도입했다. 준비 큐는 원형 큐로 동작한다. 프로세스가
1. 타임 슬라이스 전에 끝나면, 자발적으로 CPU 방출 할 것이고,
2. 타임 슬라이스 지났는데 안 끝나면 인터럽트가 발생하여, 현재 진행중이던 프로세스가 준비 큐의 꼬리로 들어간다.
라운드 로빈은 타임 슬라이스의 크기에 따라 성능이 크게 좌우된다. 현재 OS에서는 10ms~100ms 사이의 타임 슬라이스를 사용한다고 한다.
<Priority Scheduling>
이 방식은 선점/비선점 두 가지 방식 모두로 구현 가능하다. 높은 우선 순위를 가진 프로세스를 우선적으로 수행하는 방법이다. 위에서 본 SJF가 이 방식의 한 가지 예시이다. 우선 순위를 정하는 방법은 다양할 수 있다!
우선 순위 스케줄링 알고리즘에는 한 가지 문제점이 존재하는데 바로 기아(starvation) 상태이다. 우선 순위가 너무 낮은 프로세스는 하염없이 기다리다 수행도 못한다고 한다...ㅜ 이를 극복하고자 aging이라는 metric을 도입해, 나이를 지긋이 먹은(?) 프로세스의 우선 순위를 높여주는 방식을 사용한다.
<Multilevel Queue Scheduling>
우선 순위 스케줄링의 연장선상으로 보면 된다. 위의 우선 순위 스케줄링은 준비 큐에 프로세스를 다 때려넣었고, 여기서 가장 우선 순위가 높은 프로세스를 찾으려면 최악에 O(n)의 탐색이 필요할 수도 있다. 그럴거면 우선 순위 별로 큐를 따로 만들자는 방식이 바로 Multilevel Queue Scheduling이다.
이 발상은 곧 프로세스 유형에 따라 개별 큐를 갖게 하자는 발상으로 이어지는데, 다음과 같이 실시간 프로세스/시스템 프로세스/대화형 프로세스(Foreground)/배치 프로세스(Background) 를 관리하는 방식으로 관리할 수도 있다.

<Multilevel Feedback Queue Scheduling>
Multilevel Queue Scheduling의 연장선상으로 보면 된다. 위 알고리즘의 경우에는 프로세스가 시스템 진입 시 영구적으로 하나의 큐에 할당된다. 이를 탈피하는 방식으로, Multilevel Feedback Queue Scheduling에는 프로세스가 큐 사이를 이동하는 것을 허락한다.
고로 이 스케줄링 방식을 사용하기 위해서는 큐의 갯수, 각 큐의 스케줄링 알고리즘, 우선 순위가 높은 큐로 올려주기, 우선 순위가 낮은 큐로 강등 시키기, 들어갈 큐 정하기 등의 고려사항이 추가가 된다.

길다 길어! 2부에 마저 할게요~
'컴퓨터 공학 > 운영체제' 카테고리의 다른 글
| Chapter 6. 동기화 도구들 - 1부 (0) | 2020.10.20 |
|---|---|
| Chapter 5. CPU 스케줄링 - 2부 (0) | 2020.10.16 |
| Chapter 4. 스레드와 병행성 (0) | 2020.09.17 |
| Chapter 3. 프로세스 - 2부 (0) | 2020.09.17 |
| Chapter 3. 프로세스 - 1부 (0) | 2020.09.17 |




댓글