안녕하세요 조엘입니다! 프로젝트로 진행한 행렬곱셈 최적화에 대한 포스팅을 진행하도록 하겠습니다.
소스코드는 https://github.com/joelonsw/Matrix-Multiplication-Multithreading에서 확인하실 수 있습니다!

DNS알고리즘을 통해 병렬처리를 진행했지만, multi 함수는 KIJ 방식 그대로여서 LLC miss rate가 개선되지 못했습니다.
이를 개선하고자 Tiling 방법을 도입했습니다. 매트릭스의 메모리에 접근할 때, 왼쪽과 같이 탐색하게 되면, 매트릭스의 사이즈가 캐시의 사이즈보다 큰 경우,
매트릭스 탐색 후 다시 매트릭스의 첫요소에 접근할 때 캐시에 남아있지 않게 됩니다.
이를 방지하고자 Tiling 방법을 도입했는데, 이는 캐시에 남아있을 때 해당 배열에 대한 연산을 모두 수행하여 cache를 효율적으로 쓰기 위함입니다.
Multi 함수에 for문을 3개 더 작성해 주어 구현하였습니다.

Tile size를 16으로 설정해 놓고 실험해봤습니다. 사실 Cache miss rate에서 큰 변화는 보이지 않았습니다
오히려 execution time이 늘었습니다.
이는 for문을 3개 더 써 instruction의 증가로 인한 것으로 생각됩니다.
Tile size를 16에서 늘려가며 실험을 마저 진행했습니다.

LLC cache miss를 보시면, 타일 사이즈 16은 49.27%, 32는 27.79%로 감소했음을 알 수 있습니다.
타일사이즈 64와 128은 각각 4.77%, 4.69%로 LLC miss rate가 크게 감소하였습니다.

추가로 tilesize 256과 512를 진행하였는데, 오히려 이 구간에서는 LLC-miss-rate이 증가하였습니다.

타일 사이즈로 64나 128을 쓸 때 LLC miss rate이 가장 낮았습니다.
이유를 제 생각대로 한번 분석해 보았습니다.
LLC 캐시는 코어별로 1.375 메비바이트를 저장합니다. 11-way set associative 방식으로 설계되어있고, 이는 모든 코어에서 공유를 하게 됩니다.
그림을 한번 그려보았습니다.
이를 통해 캐시라인인 64바이트 * 세트 개수 2048 =
131,072 바이트 별로 같은 set에 소속된다는 것을 알 수 있었습니다.

한 코어에서 연산이 이루어지는 방식을 살펴보았습니다.
4096*4096 행렬연산 같은 경우에는 한 코어에 1024*1024행렬 3개의 데이터 접근이 이루어집니다.
KIJ 방식으로 동작하는 순서를 적어보면, A는 1번 타일을 B의 1 2 3 4 타일과 곱해 Result의 1 2 3 4 타일에 작성하고,
다음 A는 2번 타일을 B의 1 2 3 4 타일과 곱해 Result의 5 6 7 8 타일에 작성,
A는 3번 타일을 1 2 3 4 타일과 곱해 Result의 9 10 11 12 타일에 작성,
A는 4번 타일을 1 2 3 4 타일과 곱해 Result의 13 14 15 16 타일에 작성합니다.
이러한 방식으로 진행하다보니 저는 B의 1 2 3 4 타일이 LLC 캐시에 있어야 가장 성능이 좋게 나오겠다 판단했습니다.
계산을 해보았습니다.
빨간색 네모는 B의 1 2 3 4 타일을 의미합니다.
타일 사이즈 X에 따라 총 몇 바이트의 메모리에 접근하는지 계산해 보았습니다.
타일 사이즈가 64 일때, 총 262144바이트의 메모리에 접근했고, 이는 LLC 캐시의 11way 중 2way를 차지하는 용량이라고 생각했습니다.
128일 때, 총 524,288 바이트의 메모리에 접근했고, 이는 LLC 캐시의 11way 중 4 way를 차지하는 용량이라고 생각했습니다.
이 둘이 가장 이상적으로 B 행렬이 LLC캐시를 사용할 수 있는 타일 사이즈라 생각했습니다.

마지막 단계로 SIMD를 사용했습니다.
Intrinsic 함수를 사용하여 한번에 많은 데이터를 처리할 수 있게 했습니다.
SIMD를 사용한 후 2가지가 달라졌습니다.
첫번째는 instruction의 개수가 sse, avx, avx512를 쓸때마다 눈에 띄게 감소하였습니다.
두번째는 SSE/AVX를 쓸때 보다 AVX512를 쓸때, clock rate가 감소하였습니다.
Intel의 core는 3가지 모드로 사용될 수 있습니다.
License라는 이름으로 3개의 frequency level L0, L1, L2로 나뉜다고 합니다. 해당 도표에서 normal은 L0, avx2는 L1, avx512는 L2에 해당됩니다.
SISD방식과 128bit instruction(sse)은 L0로 처리가 됩니다.
Avx는 instruction이 light하다면 L0로, heavy하다면 L1으로 처리가 된다고 합니다.
Avx512는 instruction이 light하다면 L1으로, heavy하다면 L2로 처리가 된다고 합니다.
여기서 instructio이 heavy하다는 것은, FP/FMA (floating point, fused multiply-add) unit에서 SIMD인스트럭션이 수행되었을떄를 얘기합니다.
제가 짠 코드만 놓고 본다면, 모든 SIMD instructio이 heavy하다고 판단했습니다. Matrix가 float 자료형으로 선언되어 있기 때문이었습니다.
사실 실험결과를 놓고보면, 결과론적으로는 모든 instruction이 light로 처리되었습니다.
Sisd, sse, avx 방식은 모두 약 2.8GHz의 clock rate를 보였고, avx512는 약 2.3Ghz의 clock rate를 보였기 때문입니다.
제가 파악한 원인은 다음과 같습니다. AVX가 L1으로, AVX512가 L2로 진입하기 위해서는 지속적으로 heavy instruction이 수행되어야 합니다.
여기서 지속적으로는 매 사이클마다 heavy한 instructio이 필요한 수치입니다.
프로세서는 또한 heavy한 instructio을 마주치자마자 높은 license로 전환하지 않습니다. 해당 인스트럭션을 조금 느리게 수행하다가 (예를 들면 4배 느리게),
Heavy instruction이 많다고 판단이 되면 clock rate를 바꾸게 됩니다.

실험결과 입니다.
SIMD를 사용하면서 하나 더 발견한 사실은 WALL time 분에 CPU time이 감소했다는 것이었습니다.
16개의 thread를 사용했으니, 16이 나오는게 가장 이상적입니다. 하지만 simd를 사용하면서 이 수치가 감소했습니다.
각 쓰레드 별로 행렬 곱셈을 진행하는데 일찍 끝난 쓰레드를 진행한 코어는 idle상태에 빠집니다.
SIMD를 쓰면서 이 현상이 심화된 것 같습니다.

실험결과 dns알고리즘에 64사이즈로 타일링, avx512를 사용했을경우 4096*4096 행렬이 5.3초 정도 소요되었습니다.
제가 진행한 실험중에 가장 빨랐습니다.
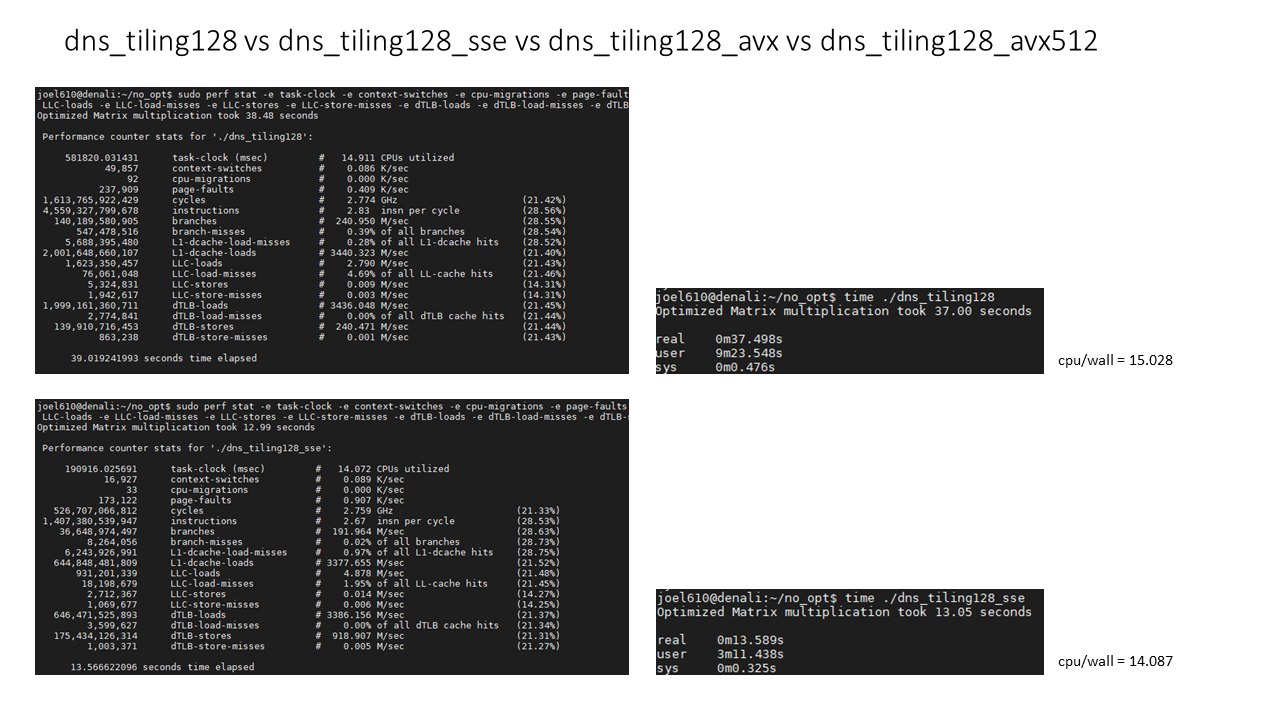

타일링을 128로 진행했을 경우 avx512를 사용했을떄 6.82초가 소요되었습니다.
사실 cache miss rate같은 경우는 타일링을 64로 진행했을 경우보다 낮았는데 더 시간이 오래걸린 이유는 CPU utilization이 더 낮기 때문입니다.
이부분은 개선이 필요하다고 생각이 들었습니다.
'프로그래밍 언어 > C++' 카테고리의 다른 글
| 행렬 곱셈 최적화 1편 (0) | 2020.07.23 |
|---|---|
| C++ 5단원 복습! (2편) (0) | 2020.03.22 |
| C++ 5단원 복습! (1편) (0) | 2020.03.22 |
| C++ 4단원 복습! (2편) (0) | 2020.03.15 |
| C++ 4단원 복습! (1편) (0) | 2020.03.14 |




댓글